BD VIAP
Base di dati VIAP
La base di dati (BD) VIAP (Varietà di Italiano – Analisi pragmatica) è stata appositamente costruita nell’ambito del progetto AMPER (Interlandi2008©) per l’analisi (macro)pragmatica di enunciati di parlato (semi)spontaneo. La BD consente, infatti, la classificazione degli enunciati in termini di modalità realizzata e permette di associare anche una descrizione del profilo intonativo emergente. Lo strumento funziona in Microsoft Access™ 2003.
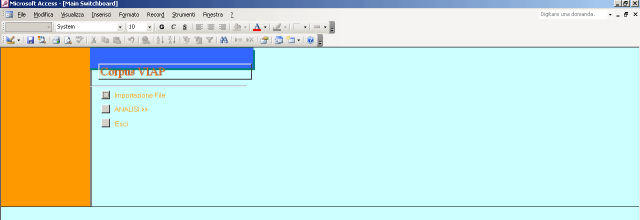
Le funzionalità previste permettono di acquisire tutte le informazioni e tutti i dati relativi a corpora di parlato precedentemente segmentati e analizzati acusticamente utilizzando AMPER-Praat. A ciascun file .wav è associato perciò un file .txt, nel quale sono automaticamente salvati tutti i dati relativi ai parametri acustici dei segmenti vocalici individuati precedentemente, e un file .gif, che presenta l’immagine globale dell’enunciato riportante oscillogramma, spettrogramma, curva intonativa e trascrizione ortografica (nella visualizzazione allineata che ne da Praat).
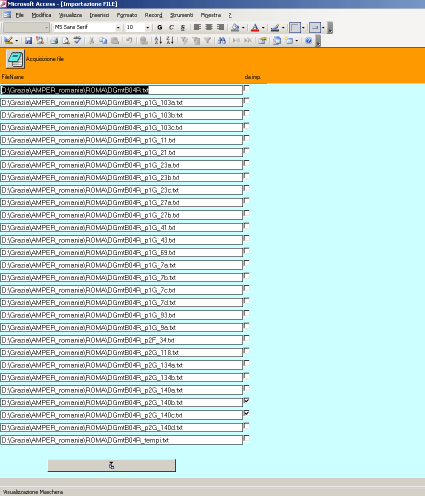
Interrogando la BD, per ciascun enunciato si dispone delle seguenti informazioni:
- varietà di italiano (indicata con la città in cui sono stati raccolti i dati);
- nome del file .txt;
- modalità dell’enunciato, nel nostro corpus DN (dichiarativa narrativa) o SFS (sospensiva di fine serie): cfr. Romano, Interlandi (in stampa), al quale si rimanda per un approfondimento del quadro teorico della ricerca;
- testo dell’enunciato (in trascrizione ortografica);
- numero delle unità intonative (UI) (1);
- profilo intonativo effettivamente realizzato e modello astratto del tonema (2) indicato per ciascuna unità intonativa presente;
- lunghezza globale delle pause (vuote o piene) eventualmente presenti;
- dati acustici per ciascun segmento vocalico (con numerazione progressiva dei segmenti, così come riportato nel file .txt relativo all’enunciato): valore della durata e valori di F0 (all’inizio, a metà e alla fine del segmento, indicati come F01, F02 e F03); in questa tabella riassuntiva è possibile anche etichettare, per ciascuna unità intonativa, le vocali del tonema come VPRT (vocale pretonica), VT (vocale tonica) e VPT (vocale postonica);
- immagine .gif riportante l’oscillogramma, lo spettrogramma, la curva intonativa e i due livelli di trascrizione allineati (parole e vocali).
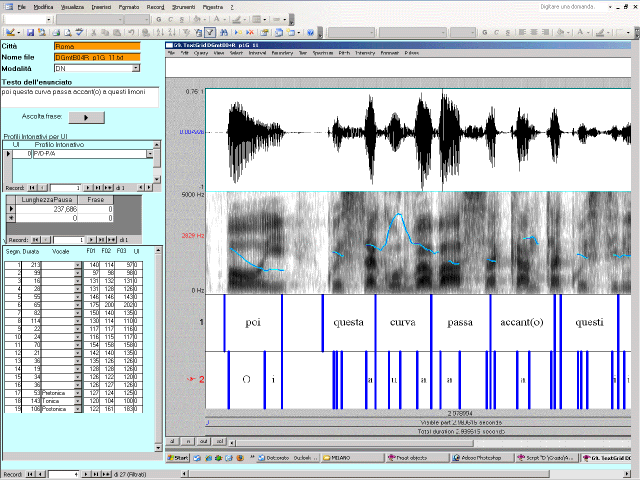
È possibile interrogare la BD attraverso una funzionalità di analisi del corpus organizzata per segmenti vocalici: in questo caso è necessario scegliere la varietà di italiano e la modalità degli enunciati che si intende analizzare. Una volta effettuata la scelta nei menù a discesa, si dispone di una tabella riassuntiva in cui, per ciascun segmento vocalico classificato come VPRT, VT o VPT del tonema di un certo enunciato (indicato dal nome del file) sono visualizzati i valori rispettivamente di intensità, durata e F0 (nei tre punti del segmento in cui vengono rilevati) e in più la durata relativa (percentuale) del segmento vocalico (calcolata sulla durata del segmento compreso tra inizio della vocale e secondo valore di F0 rilevato, ossia F02). Inoltre per ciascuna vocale viene visualizzato automaticamente il profilo intonativo realizzato sul singolo segmento (con una soglia percettiva di ± 10 Hz) e viene attribuita la classificazione del profilo, abbinata alla modalità dell’enunciato (es. DICH NARR – P/D/A).

All’interno della BD sono state impostate iinfine due funzionalità diverse di esportazione dei dati in fogli di lavoro elettronici (3).
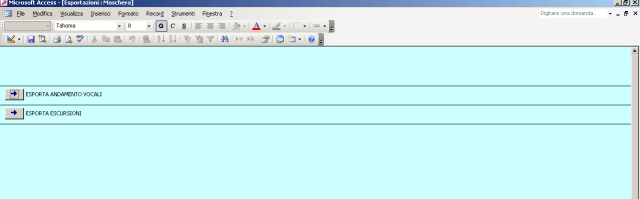
In questo modo, esportando i dati, si dispone di due tabelle separate (l’una organizzata per file di testo, l’altra organizzata per vocali del tonema), a partire dalle quali è possibile impostare l’analisi di tipo statistico. Utilizzando le informazioni contenute nei fogli elettronici di lavoro è possibile calcolare ad es.:
- la frequenza nel corpus di DN e SFS in relazione alle diverse varietà di italiano;
- la frequenza dei diversi profili e modelli intonativi rilevati;
- l’escursione melodica media realizzata su VPRT-VT-VPT del tonema;
- la velocità del movimento, ossia la pendenza media della curva realizzata sul tonema, calcolata come rapporto tra escursione melodica in Hz e durata in ms. di ciascuna vocale;
- il peso vocalico, cioè il rapporto tra durata di ciascuna vocale (VPRT, VT e VPT del tonema) e durata media delle vocali realizzate in ogni singolo enunciato (4).
HTML, CSS and design by Paolo Mairano